Python 초보자를 위한 FastAPI(3) 1
Part 2에서 OpenAPI에 대한 소개 글을 쓸까 생각했었다. 하지만 코딩을 더 해보고 싶다는 생각이 들었다. 그래서 시작하겠다.
라우팅과 디렉토리 구조
지난번까지 저자의 main.py 파일 안에 무언가를 작성했다. 모든 것이 잘 작동하지만 파일에 계속 코드를 추가할 수는 없다... 코드를 다른 파일로 정리하는 더 좋은 방법이 분명히 있겠죠?
저자는 첫날부터 Python을 배우기 시작했다. Python에서는 모든 디렉토리(또는 진영에 따라 폴더)가 하나의 패키지이고 모든 파일이 모듈이라는 것을 배웠다. 따라서 새 패키지를 만들고 싶으면 새 디렉터리를 만들기만 하면 된다.
지난번에 남긴 내용은 다음과 같다.
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Track(BaseModel):
title: str
artist: str
album: str | None = None
year: int
label: str | None = None
tracks: list[Track] = []
@app.get("/")
async def root():
return {"Hello": "World!"}
@app.get("/tracks")
async def get_tracks():
return tracks
@app.post("/tracks")
async def create_track(track: Track):
tracks.append(track)
return track
모든 tracks 관련 경로를 포함하는 새로운 tracks 모듈을 만들고 싶다. 그래야 main.py가 모든 코드로 인해 폭증하지 않을 것이다. 아이디어는 routers라는 새 패키지를 만들어 tracks 모듈을 포함한 모든 모듈을 그 안에 넣는 것이다. 모든 것이 올바르게 작동하면 main.py에 from routers import tracks, SOME_OTHER_MODULE, ...을 사용할 수 있다.
app
├── __init__.py
├── main.py
├── routers
├── __init__.py
├── tracks.py
dockerfile
docker-compose.yml
requirements.txt
routers라는 디렉터리와 tracks.py 파일, 그게 다이다! 하지만 routers 디렉터리 아래에 빈 __init__.py 파일도 생성한다. 다시 말하지만, 이것은 필수는 아니지만 언젠가는 필요할 것 같다. 그리하여 그냥 두겠다.
이제 모든 tracks 관련 코드를 새 파일로 옮길 차례이다. 하지만 그 전에 새 파일에서 app이 작동하도록 하는 방법을 알아내야 하는데, 지금까지는 @app.get(...)을 사용하여 새 경로를 만들었기 때문이다. 그렇다면 app을 새 track 파일로 가져와야 할까? 순환 가져오기 같은 것인가? Python에 대해서는 잘 모르겠지만 이것은 옳은 일이 아닌 것 같고 분명히 문제를 일으킬 것이다.
정답은 fastapi 내부에 app에서 사용할 수 있는 새로운 경로를 생성할 수 있는 APIRouter 모듈이라는 모듈이 있다는 것이다. 알면 절반은 성공한 것입니다. 이제 tracks 모듈을 구현할 차례이다.
from fastapi import APIRouter
router = APIRouter(
prefix="/tracks",
tags=["Tracks"],
# response=({404: {"description": "Not Found"}})
)
@router.post("")
async def create_track(track: Track):
tracks.append(track)
return track
router 변수를 APIRouter로부터 만들었다. 여러 속성으로 APIRouter를 초기화할 수 있지만, 현재는 일부 속성만 신경 쓰고 있다.
prefix- 이 엔드포인트의 URL을 의미한다.tags- 문서에 멋진 태그를 제공한다.response- 기본 응답이다. 따라서 누군가 예기치 않은 URL을 누르면 이 응답으로 되돌아간다.
여기에는 흥미로운 점이 있다. 첫째, tag 속성은 list이므로 이 경로를 다음과 같이 여러 개의 태그된 섹션 아래에 넣을 수 있다.
위 그림과 같다. track 경로에 Track과 Track2 두 태그가 있다. 멋지긴 하지만 지금은 별로 유용하지 않다.
그리고 두 번째는 prefix 속성의 이름입니다. "prefix"는 이 경로 아래의 모든 것을 나타내며, 모든 경로 앞에 이 접두사를 자동으로 적용한다. 그래서 @router.post("/")를 그대로 두었다. 누군가 이 엔드포인트를 호출하려는 경우 localhost/tracks가 될 것이다. 따라서 경로가 커지면 각 엔드포인트에 /tracks을 넣는 수작업을 생략할 수 있다.
다음 단계는 새 APIRouter를 app에 연결하는 것이다. FastAPI 인스턴스 내부에는 새로 생성된 경로를 app에 넣을 수 있는 include_router라는 메서드가 있다.
from fastapi import FastAPI
from routers import tracks
app = FastAPI()
app.include_router(tracks.router)
매우 쉽다. tracks 모듈을 가져와서 include_router 메서드를 호출하기만 하면 된다.
하지만 마음에 들지 않는 부분이 있다... 모든 라우터의 prefix를 한 눈에 볼 수 있으면 좋겠다. 그러면 경로 prefix를 변경해야 할 때 파일을 일일이 찾아서 변경할 필요가 없으니 큰 도움이 될 것 같다(또는 매크로를 기록해서 변경할 수도 있겠지만... 서툴러서 오히려 재앙이 될 수도 있겠다).
그리고 FastAPI에는 우리의 필요에 대한 솔루션이 있다.
from fastapi import FastAPI
from routers import tracks
app = FastAPI()
fallback = {404: {"description": "NotFound"}}
app.include_router(tracks.router, prefix="", tags=["Tracks"])
# app.include_router(tracks.router, prefix="/tracks", tags=["Tracks"], response=fallback)
@app.get("/")
async def root():
return {"Hello": "World!"}
첫 번째 인자 다음에는 include_router는 기본적으로 APIRouter로서 모든 매개 변수를 포함한다. 이제 모든 라우터 prefix를 한 곳에서 볼 수 있다. 우리는 다른 방법보다 이 방법을 더 선호한다. 수정 후 tracks 모듈 내부의 APIRouter를 비워둘 수 있다.
이제 프로젝트를 구성하는 방법과 앱에 새 경로를 추가하는 방법을 배웠다. 다음에는 파라미터를 사용하는 방법에 대해 조금 더 알아보고자 한다.
파라미터 기초
매개변수에는 Path와 Query 두 종류가 있다.
path 매개변수는 엔드포인트 경로의 일부이다. 특정 ID로 블로그 게시물을 요청하는 클래식 RESTful API를 살펴보면 /posts/1과 같이 보인다. path 매개변수는 /1이다. 매개변수인 이유는 상호 교환이 가능하기 때문이다. ID가 2인 다른 게시물을 원한다면 /posts/2가 된다. 하지만 엔드포인트는 동일하게 유지되며 항상 /posts이다. path 매개변수를 사용하면 API를 더 깔끔하게 만들 수 있다.
query 매개변수는 보다 전통적인 방법으로, URL의 search(query) 매개변수 부분에 속한다. 가장 깔끔한 방법은 아니지만 유연성이 뛰어나며 보다 정교한 사용을 위해 필요하다. query 매개변수는 URL에 ? 뒤에 있는 모든 것을 의미한다. 예를 들어 "John"이라는 사람이 작성한 모든 글을 찾고자 한다면 /posts?author=john과 같은 형식이 될 수 있다.
path 쿼리가 할 수 있는 모든 작업을 query 매개변수로도 수행할 수 있기 때문에 쿼리 매개변수만 사용할 수 있다. 예를 들어 /posts?id=1&author=john과 같은 것을 사용하면 된다. 하지만 클라이언트 측에서 보기에도 좋지 않을 뿐 아니라 모든 코드를 하나의 경로 안에 넣게 된다. 최선의 아이디어는 아니다. 분명히 두 가지 모두 필요할 것이다.
나중에 사용할 수 있는 테스트 데이터를 만들어 본다.
class Track(BaseModel):
id: int
title: str
artist: str
album: str | None = None
year: int
label: str | None = None
tracks: list[Track] = [
{
"id": 1,
"title": "Here comes the sun",
"artist": "Beatles",
"album": "Abby Road",
"year": 1969,
"label": "Apple Records",
},
{
"id": 2,
"title": "Song 2",
"artist": "Blur",
"album": "Blur",
"year": 1997,
"label": "Parlophone",
},
{
"id": 3,
"title": "High & Dry",
"artist": "Radiohead",
"album": "The Bends",
"year": 1995,
"label": "EMI",
},
{
"id": 4,
"title": "The Rain Song",
"artist": "Le Zeppelin",
"album": "Houses of The Holy",
"year": 1973,
"label": "Atlantic Records",
},
]
Track 클래스에 id 속성을 추가하였다. 나중에 새로 생성된 path 매개변수로 찾을 수 있도록 도와줄 것이다. 그리고 track 변수에 몇 곡을 채웠다.
다음으로 path를 /{track_id}로 설정한 새 경로를 생성한다.
@router.get("/{track_id}")
async def get_track_by_id(track_id: int):
for track in tracks:
if track["id"] == track_id:
return track
라우트 path의 중괄호 안의 track_id가 get_track_by_id 인수와 이름이 같다는 것을 알 수 있다. 이는 기본적으로 path 매개변수를 사용하는 방법이다. 따라서 이론적으로는 /{track_id}/{SOME_OTHER_PARAM}과 같은 path 쿼리를 여러 개 가질 수 있다. 하지만 지금은 필요 없을 것 같다.
그런 다음 루프에서 for in를 사용하여 tracks 리스트를 살펴보고 트랙 id가 track_id 매개 변수와 같으면 트랙을 반환한다.
이 방법은 아이디를 가진 트랙이 존재하는 한 잘 작동한다. 아이디가 존재하지 않는다면 그냥 null을 반환한다. 그냥 null을 반환하는 것이 잘못된 것은 아니지만 더 나은 방법이 있을 것이다.
from fastapi import APIRouter, HTTPException
@router.get("/{track_id}")
async def get_track_by_id(track_id: int):
for track in tracks:
if track["id"] == track_id:
return track
raise HTTPException(status_code=404, detail="Track not found")
적절한 HTTP 예외를 생성하는 데 사용할 수 있는 HTTPException 클래스가 내장되어 있다. 이제 누군가 존재하지 않는 노래를 요청하면 404 찾을 수 없음이라는 응답을 받게 된다.
누군가 트랙 ID로 정수 대신 문자열을 보내면 어떻게 될까? 다행히도 Pydantic이 이를 처리할 수 있다. Swagger UI에서는 요청을 실행하지 않고 매개변수가 정수여야 한다는 명확한 경고를 표시한다. 하지만 Swagger UI에서 직접 요청을 보내면 다음과 같은 오류가 발생한다.
{
"detail": [
{
"type": "int_parsing",
"loc": [
"path",
"track_id"
],
"msg": "Input should be a valid integer, unable to parse string as an integer",
"input": "HELLO",
"url": "https://errors.pydantic.dev/2.3/v/int_parsing"
}
]
}
tracks/HELLO로 엔드포인트에 액세스하려고 할 때이다. 그리고 422 처리할 수 없는 엔티티 상태도 표시된다.
이 경로는 정상적으로 작동하는 것 같다. 이제 /tracks 경로가 페이지내이션(pagination)을 수행하고 아티스트를 검색할 수 있는 몇 가지 query 매개변수를 허용하도록 만들자.
@router.get("")
async def get_tracks(skip: int = 0, limit: int = 1, q: str | None = None):
matched: [Track] = []
if q:
for track in tracks:
if track["artist"].lower() == q.lower():
matched.append(track)
else:
return tracks[skip : skip + limit]
return matched[skip : skip + limit]
query 매개변수를 정의하는 방법은 간단하다. get_tracks 함수의 인수로 query 이름을 추가하기만 하면 된다. 페이지내이션을 위해 skip과 limit을 추가하여 오프셋 기반 페이지내이션으로 만들고, 사용자가 limit을 사용하여 한 요청에 원하는 트랙 수와 skip으로 리스트의 시작할 위치를 선택할 수 있도록 했다. 그리고 아티스트 검색을 위한 q 매개변수도 있다.
지금은 q가 여러 속성을 검색할 수 있도록 허용하여 너무 복잡하게 만들지 않겠다. 코드에서 이를 구현하는 데 많은 오버헤드가 발생하고 데이터베이스 통합을 시작하면 곧 삭제될 것이기 때문이다.
그래서 코드에서 검색 기준과 일치하는 모든 트랙을 저장할 수 있는 새로운 marched 변수를 선언하고 시작한다. 그런 다음 q에 값이 있는지 확인한다.
q가 None이면 선택한 범위의 tracks만 반환한다. Python에서는 [START_INDEX : END_INDEX]로 리스트에 접근하여 특정 범위의 항목을 검색할 수 있다. 따라서 tracks[skip : skip + limit]는 기본적으로 skip에서 skip+limit까지 트랙 항목을 원한다는 뜻이다. 꽤 편리하다.
q에 값이 있다면. 그런 다음 tracks 리스트를 살펴보고 아티스트 q가 만든 트랙이 있는지 찾아서 matched 변수에 추가한다. 그리고 동일한 로직을 적용하여 matched 리스트의 특정 범위를 선택한 후 matched를 반환한다.
아주 최적화된 코드는 아니다. 트랙이 충분히 추가되면 루프를 끊길 수 있다. 하지만 다시 한 번 SQL에 맡기도록 한다.
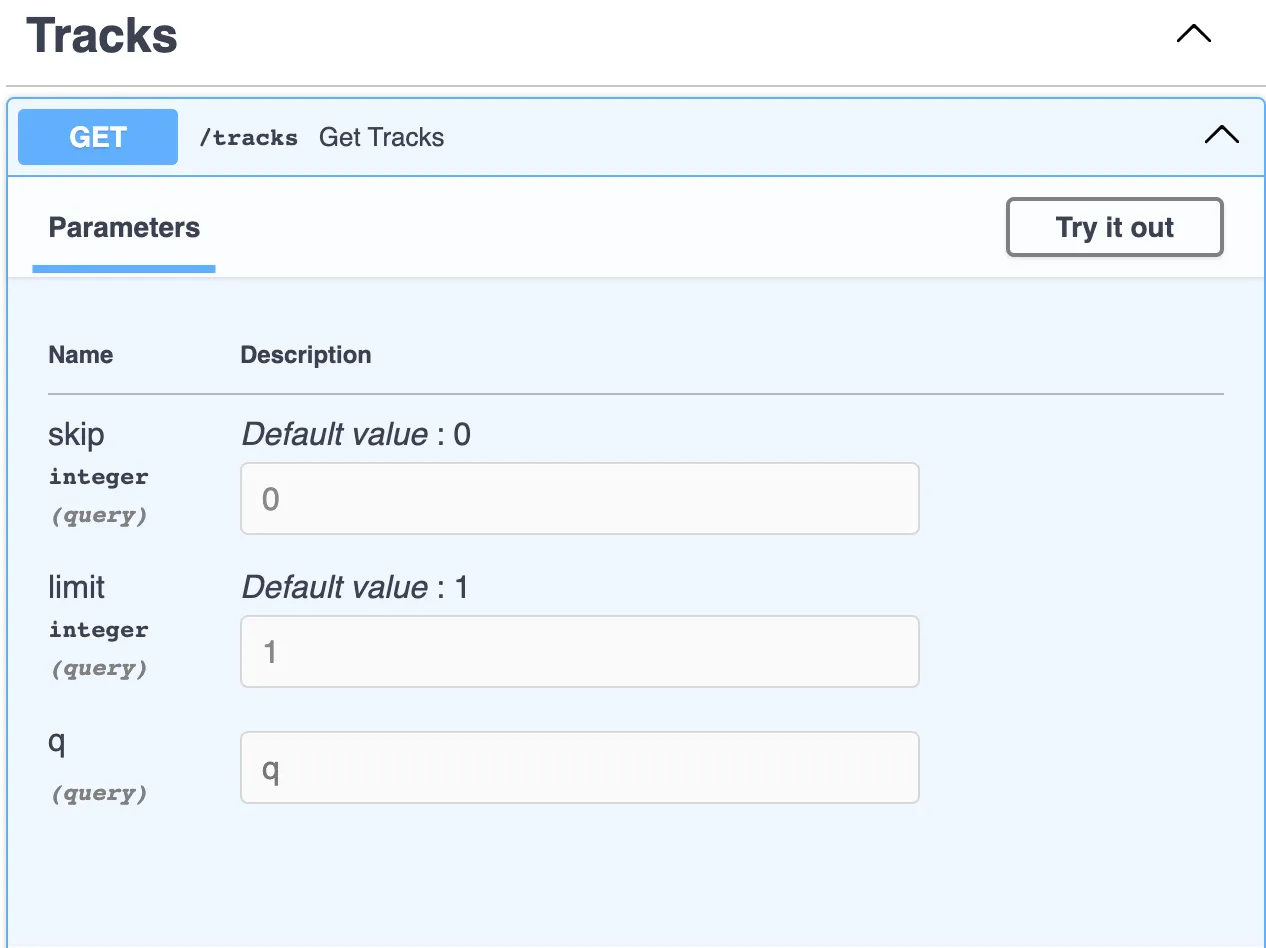
이제 Swagger로 이동하여 매개변수 섹션에서 /tracks에 모든 query 매개변수가 있는 것을 확인할 수 있다. 아티스트별로 트랙을 검색할 수 있고, 한 요청에서 원하는 트랙 수를 설정할 수 있다. 모든 것이 작동한다!
트랙을 찾을 수 없는 경우 오류를 발생시키지 않는 /tracks/{track_id} 경로와 달리 이 엔드포인트는 빈 리스트일지라도 항상 트랙 리스트를 반환한다. 프론트엔드 코드 작업을 시작할 때 작업하기가 더 쉬워질 것이다.
이 파트는 여기까지이다. API를 만들 때 정말 중요한 구성 요소는 두 가지 정도밖에 없다고 생각한다. 하나는 인증과 권한 부여인데, 이는 꽤 까다로울 수 있다. 이러한 주요 주제가 끝나면 코드에 더 많은 지면을 할애하고 사물과 아이디어를 설명하는 데는 더 적은 지면을 할애할 것이다.
1: 이 페이지는 FastAPI by A Python Beginner (3)을 편역한 것임.